

Nvidiaはテキストプロンプトから3Dモデルを生成できるジェネレーティブAI「Magic3D」を発表した
米国カリフォルニア州に拠点を置く半導体メーカー大手 Nvidia は、テキストプロンプトから3Dモデルを自動で生成できるジェネレーティブAI「Magic3D」を発表した。

3Dモデリング用のジェネレーティブAI「Magic3D」は、複雑で有機的なカラーテクスチャ付きの3Dメッシュモデルを僅か数十分で生成することが可能で、事例として紹介されている「睡蓮の上に座るコバルトヤドクガエル」は、プロンプトを入力した直後に得られた物で、特別な訓練を必要とせずに誰でも簡単に3Dモデルを作成できるようになることを示している。このプロセスで得られた3Dデータに改良を加えれば、CGIアートシーンやビデオゲームに活用することも可能となる。

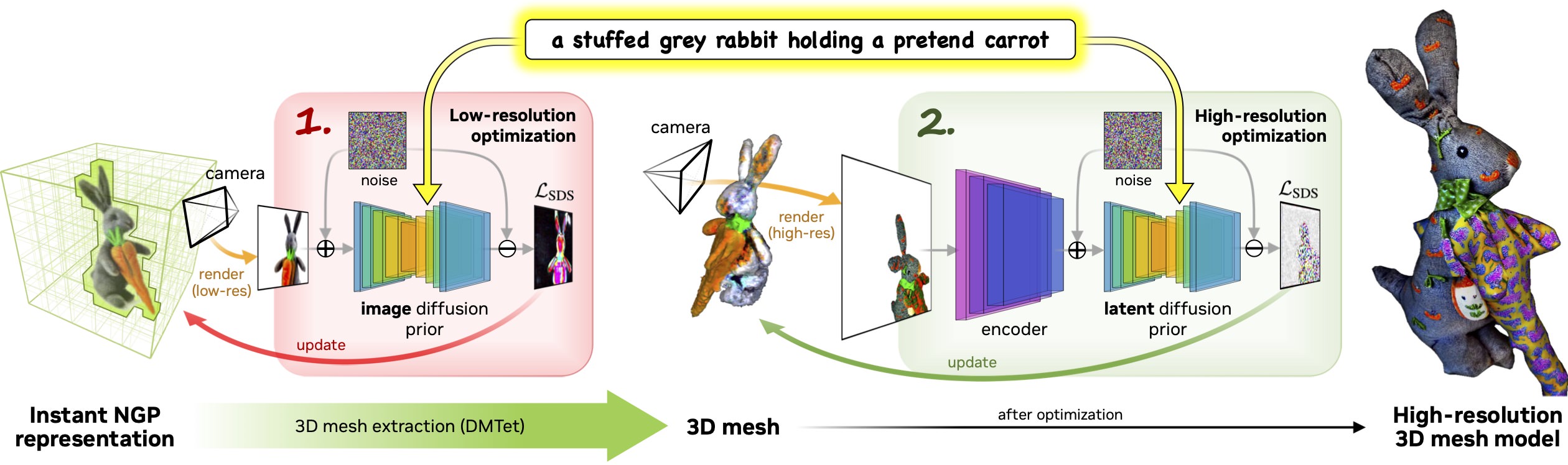
「Magic3D」は、Googleの研究チームが2022年9月に発表した、テキストから3Dモデルを生成する「DreamFusion」に対抗するシステムとされている。DreamFusionは、学習済みのテキストから画像への拡散モデルを使用して「Neural Radiance Fields (NeRF) 」を最適化し、テキストから3Dへ合成結果を達成することを実証したが、この方法には「NeRFの最適化が非常に遅いこと」と「NeRFでの低解像度の画像空間の監視が原因で、処理時間が長い低品質の3Dモデルが生成される」という2つの制限がある。ホワイトペーパーによれば、2段階の最適化フレームワークを利用して、これらの制限に対処するとしている。
先ず、低解像度の拡散事前分布を使用して粗いモデルを取得し、疎な3Dハッシュグリッド構造で加速。 粗い表現を初期化として、高解像度の潜在拡散モデルと相互作用する効率的な微分可能なレンダラーを使用してテクスチャ付きの3Dメッシュモデルをさらに最適化するが、「Magic3D」は高品質の3Dメッシュモデルを僅か40分で作成できる。これは、DreamFusionよりも2倍速く、さらに高い解像度も実現する。 ユーザー調査では、61.7%の評価者がDreamFusionより「Magic3D」のアプローチを好むことを示しており、 画像調整された生成機能と共に、3D合成を制御する新しい方法をユーザーに提供し、さまざまなクリエイティブ アプリケーションへの新しい道を開くとしている。
また「Magic3D」は、プロンプトベースの3Dメッシュ編集も可能で、ベースとなるプロンプトと低解像度の3Dモデルがあれば、テキストを変更することでモデルを編集することができる。
高速で高品質のテキストから3Dコンテンツを作成するため、2段階の粗いものから細かいものへの最適化フレームワークを利用。 最初の段階では、低解像度の拡散事前分布を使用して粗いモデルを取得し、これをハッシュ グリッドとスパース アクセラレーション構造で加速。 第2段階では、粗いニューラル表現から初期化されたテクスチャメッシュモデルを使用して、高解像度の潜在拡散モデルと相互作用する効率的な微分可能なレンダラーで最適化を可能にする。
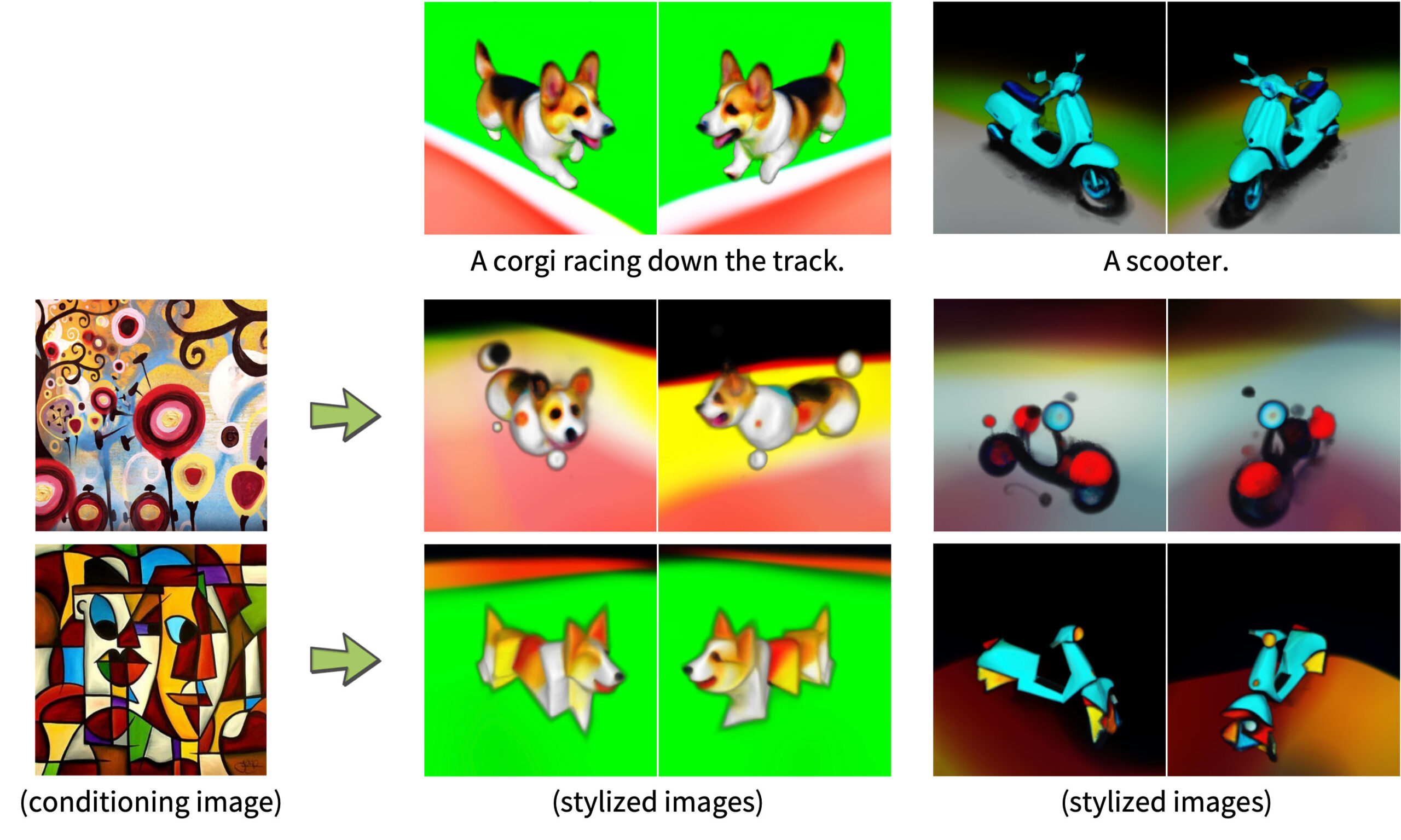 入力画像の拡散モデル (eDiff-I) を調整し、そのスタイルを出力3Dモデルにに反映させることができる
入力画像の拡散モデル (eDiff-I) を調整し、そのスタイルを出力3Dモデルにに反映させることができる
Nvidiaは、「Magic3D」によって3D合成を民主化し、3Dコンテンツ制作におけるすべての人の創造性を開放することができると期待している。
関連記事
- テキストから3Dモデルを生成する「Point-E」
- AIベースの設計ソフトウェアを一般公開
- 3Dプリントによる植物由来の電気自動車を発表
- 人体の構造わかる3D人体解剖学アプリ「teamLabBody Pro」
- Stratasysの全自動3Dプリンティング生産セル
- Stratasysがソフトウェア会社Rivenを買収
3DP id.arts の最新投稿をお届けする「Newsletter 3DP id.arts」への登録はこちら
最新情報をお届けします
Twitter でid.artsをフォローしよう!
Follow @idarts_jp





